2024 年 ApacheCon 北美之旅的收获与感悟
Apache HoraeDB 是 2023-12-11 加入 Apache 孵化器,由此拉开了我在 Apache 社区的成长探索之旅。作为一个历史悠久的基金会,Apache 旗下的软件可谓家喻户晓:Hadoop、Spark、Kafka 等等。 在这次 2024 年的 ApacheCon 北美大会上,我有幸代表 HoraeDB 社区参加,终于有机会来近距离和来自世界各地的 Apache 项目的 PMC 们交流。这次经历不仅让我深入理解了 Apache 项目的核心价值与贡献,还深刻认识到开源社区如何驱动技术创新、促进开发者之间的协作与分享。
这次大会在丹佛的君悦大酒店举行,为期四天(2024-10-07 ~ 10),讨论涉及搜索、大数据、物联网、社区等多个方面,从现场来看,讲师比嘉宾还要多,除了 Keynote 分享是在一个大会场进行,其他的场子均在一个小房间里,每个房间外会有一个电子屏展示今日的议题。全部日程见官网 Sessions Schedule。

文化差异
在介绍具体议题之前,我想先简单介绍下与会过程中感受到的中美间的文化差异,以飨读者。
和国内会议类似,第一天议程结束后有个晚宴(event reception),但这个晚宴可不“简单”,不是传统的晚宴,社交属性更重些。场地内会有几个比较高的圆桌,大家在旁边拿完东西后就可以找感兴趣的人开聊。对于第一次参见这种会议的我来说,其实有是些蒙的,和一同去的同事默默站在一角观望可以插入的场子,但看着周边人群在慷慨激昂的谈论时,发现自己不能很轻松地加入:一是语言问题;二就是文化差异。
在转了几圈后,发现几个国人面孔,通过沟通知道了他们都来自苹果公司,苹果是这次的大赞助商,所以他们大概来了四五十人!只不过组比较多,所以很多人也是第一次见面。听他们说这种聚会形式在美国挺常见的,他们虽然在美已经多年,语言早已不再是什么问题,但碍于文化差异,他们也不能很轻松的融入进去。
通过交流,了解到苹果公司内很多基建都是基于 Apache 的项目构建,而且最近几年他们在开源上的力度也越来越大,印象较深的就是 Swift 语言,其中一个女士貌似是 Swift 的 team member,她看到我穿的是带有 Rust logo 的衣服,就建议我尝试下 Swift,这两个语言设计理念类似,但 Swift 更简单,而且为了避免苹果一家独大,他们已经把 Swift 迁移到独立的 GitHub 组织上去。此外,Swift 也不仅仅是苹果平台的特定语言,他们也花了很多精力来保证 Swift 在 Linux/Windows 上也能完美的运行。
可以想到,苹果把 Swift 定位为通用语言,既可以为苹果生态服务,也是更长远的战略布局。通过通用化,苹果能够扩大 Swift 的生态影响力,吸引更多开发者进入其体系,同时为跨平台的未来做好准备。现在想想,华为的仓颉语言 也是类似思路。打造生态前期投入肯定是巨大的,需要长期投入和耐心的过程,但对大企业来说,这种投入实际上是一种战略性资源配置,目的就是建立长期的技术竞争力。
在会场中,我也有幸见到了 Database Internals 一书的作者 Alex Petrov(目前在苹果工作),给他简单介绍了下 HoraeDB,他的本能反应就是 Very cool!在国内我还真没遇到类似回答。
演讲介绍
接下来就介绍几个笔者印象比较深的演讲,由于没有演讲时的 PPT,因此下面的介绍是我根据印象中的关键词搜索整理的,仅供大家参考。
Optimizing Apache HoraeDB for High-Cardinality Metrics at AntGroup
这是我带来的演讲,介绍了 HoraeDB 重点解决的问题,以及对应思路和方法。核心一点就是通过 AP 领域的思路(剪枝、BRIN)来解决高基数时间线的问题,细节可以参考本次分享的PPT。
现在的版本我们其实也遇到了些新问题。目前的引擎在以时序分析为主的场景来说运行的会比较好,但在传统的时序告警领域工作的并不是很好,主要在于两点:
- 一次查询的代价太大,在查询引擎中采用了通用的 Arrow 格式,反而导致丢失了针对时序特点的优化
- 采用表作为基本数据组织方式过于严格,时序本来是一种弱 Schema 的场景,而提前定义好固定模式的表显然是一种“退步”,另外表作为资源管理单位,也限制了单机能够承载的表数量。
因此在后续的版本中,我们吸取了现在引擎(即目前的 Analytic Engine)的教训,打算重新设计一种引擎(称为:Metric Engine)来解决高基数的问题。
新引擎正在紧锣密鼓的开发中,感兴趣的读者可以参考这里的 RFC 来了解设计思路。在后续的版本发布时,我们也会重点强调新引擎的开发进度。
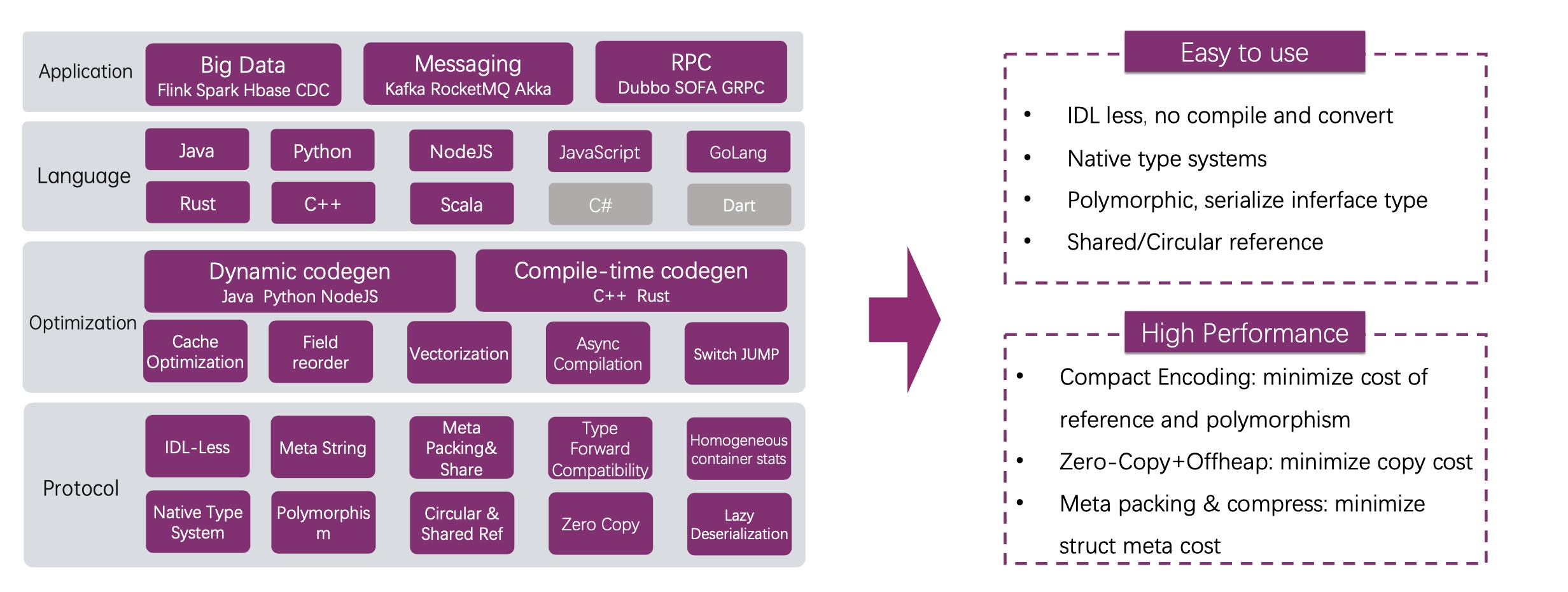
Blazingly-Fast: Introduction to Apache Fury Serialization
演讲者是 Fury 项目的发起者 Shawn Yang,也是我的同事。如标题所说,Fury 定位的就是高效的序列化,已经在诸多系统中被使用(参见:Who is Using Apache Fury?),并取得显著提升。
一直以为序列化是个已经解决的问题,了解了 Fury 后才了解到这个领域的问题。举个简单的例子,对于常见的 Protobuf 来说, 在序列化一个数组的 Message 时,Message 的元数据会序列化多次,但如果应用层能够保证每个字段都不会缺失,那么这样就是有些浪费的,在 Fury 中就可以 schema consistent 这种模式来避免这种冗余。
Making Apache Kafka even faster and more scalable
Kafka 是一种高吞吐量的分布式流处理平台,尽管十分流行,但近些年随着使用场景的复杂,挑战者也不少,比如:
- 主打云原生的 Pulsar
- 金融级可靠性的 RocketMQ
- 强调低延迟的 RabbitMQ
这个议题的嘉宾来自 Instaclustr,提供托管的 Kafka 服务。他主要从两方面来讲述了对 Kafka 的改进:
- 使用 KRaft 替换 ZooKeeper,这个主要是为扩大分区数考虑,分区是 Kafka 里很重要一概念,是进行并发读写的基本单位,在嘉宾的测试中,基于 ZK 的版本最高可以达到八万个分区,而基于 KRaft 的版本可以达到近两百万的分区。细节可以参考:Kafka Control Plane: ZooKeeper, KRaft, and Managing Data。
- 分层存储(Tiered storage),冷热数据分离的标配,通过将访问低频的数据移动到 S3 上可以显著降低成本。KIP-405 最早在 2020 年就提出来了,3.6.1(2023) 发布到期访问版,3.8.0(2024) 发布 V1 正式版。
Tomcat 11 and Jakarta EE 11
Tomcat 是 Java Web 开发领域的一个经典开源项目,不仅仅是一个 Web 服务器和 Servlet 容器,更承载了许多开发者的回忆。虽然不写 Java 很多年了,但看着到这个项目还是挺亲切的,毕竟谁能不喜欢这只 Tom 猫呢?

这个议题里分享了最新的 11 版本中的特性:
- 最小支持的 Java 版本升级到 17
- 通过 FFM 支持与 OpenSSL 集成(需要 Java 22+)
- 增强基于虚拟线程的执行器(VirtualThreadExecutor)
- 日志增加 JSON 输出格式
- 移除以下功能
- Security Manager support
- 32-bit Windows support
- HTTP/2 Server push support
都是些与时俱进的功能,记得在很早就看过 HTTP2 的 Push 功能有些鸡肋,这个案例说明了一个重要的原则:有时看起来很好的技术特性,在实际应用中可能并不如预期。
Cassandra
Cassandra 议题这次会议上非常多,印象中有一个房间一整天的议题都是与之相关,没想过 Cassandra 能有这么流行,甚至还有一个 BYOT(Bring Your Own Topic) 环节,来让大家交流 Cassandra 使用心得。下面是几个重量的议题:
- The Road to 20 Terabytes per Node: Overcoming Cassandra’s Storage Density Challenges
- Apache Cassandra as a Transactional Database
- Lessons from (Probably) the World’s Largest Kafka and Cassandra Migration
遗憾的是,由于演讲者说话速度较快,再加上我对 Cassandra 了解较少,大部分议题未能完全领会,只能课下再下功夫了解了。但尽管如此,还是对一个议题印象颇深,是一个由满脸白胡子的嘉宾分享的关于在查询中实现分页的演讲,很工程的一个问题,演讲者围绕其对性能的影响、潜在的误用风险等多个维度进行了详尽剖析,展现出深厚的专业功底和匠人精神。

ODBC takes an Arrow to the knee: ADBC
Apache Arrow 是一个跨语言的内存数据处理框架,通过标准化内存中的列式数据表示来实现高效的数据交换和处理。 和 JDBC 类似,ADBC 是基于 Arrow 的、供应商中立的 API,方便用户高效查询支持 Arrow 的数据库,比如 DuckDB,就有 38 倍的提升!
其他
Apache YuniKorn,云原生时代的资源调度器,和现场一个苹果的朋友聊,他们就在用它来调度他们 AI 相关的任务!
PRQL(Pipelined Relational Query Language),另一个查询语言,相比 SQL 功能更强大、简洁。示例:
1 2 3 4 5 6 7from tracks filter artist == "Bob Marley" # Each line transforms the previous result aggregate { # `aggregate` reduces each column to a value plays = sum plays, longest = max length, shortest = min length, # Trailing commas are allowed }对应的 SQL 如下:
1 2 3 4 5 6 7 8SELECT COALESCE(SUM(plays), 0) AS plays, MAX(length) AS longest, MIN(length) AS shortest FROM tracks WHERE artist = 'Bob Marley'
总结
参加这次 Apache 大会,HoraeDB 项目算是首次走向国际舞台。与那些已广为人知、炙手可热的项目相比,我们仍然任重而道远。 一个开源项目能够在核心开发团队不断更迭的情况下持续演进,本身就是极其难能可贵的。在 Apache 基金会,我看到了诸多值得学习的典范。
归根结底,软件的生命力在于人,唯有不断壮大社区,源源不断地吸引卓越人才,才能确保社区生生不息、薪火相传。 HoraeDB 目前正处于起步阶段,期许通过社区的持续努力和协作,最终能打造出一个世界一流的云原生时序数据库,在开源的广阔天地中绽放光彩。
欢迎感兴趣的朋友加入我们:https://horaedb.apache.org/community/