This is the multi-page printable view of this section. Click here to print.
用户指南
1 - SQL 语法
本章介绍 HoraeDB 的 SQL 使用语法。
1.1 - 数据模型
本章介绍 HoraeDB 的数据模型。
1.1.1 - 数据类型
HoraeDB 实现了 Table 模型,支持的数据类型和 MySQL 比较类似。
下列表格列出了 HoraeDB 的数据类型和 MySQL 的数据类型的对应关系。
支持的数据类型 (大小写不敏感)
| SQL | HoraeDB |
|---|---|
| null | Null |
| timestamp | Timestamp |
| double | Double |
| float | Float |
| string | String |
| Varbinary | Varbinary |
| uint64 | UInt64 |
| uint32 | UInt32 |
| uint16 | UInt16 |
| uint8 | UInt8 |
| int64/bigint | Int64 |
| int32/int | Int32 |
| int16/smallint | Int16 |
| int8/tinyint | Int8 |
| boolean | Boolean |
| date | Date |
| time | Time |
1.1.2 - 特殊字段
HoraeDB 的表的约束如下:
- 必须有主键
- 主键必须包含时间列,并且只能包含一个时间列
- 主键不可为空,并且主键的组成字段也不可为空
Timestamp 列
HoraeDB 的表必须包含一个时间戳列,对应时序数据中的时间,例如 OpenTSDB/Prometheus 的 timestamp。
时间戳列通过关键字 timestamp key 设置,例如 TIMESTAMP KEY(ts)。
Tag 列
Tag 关键字定义了一个字段作为标签列,和时序数据中的 tag 类似,例如 OpenTSDB 的 tag 或 Prometheus 的 label。
主键
主键用于数据去重和排序,由一些列和一个时间列组成。 主键可以通过以下一些方式设置:
- 使用
primary key关键字 - 使用
tag来自动生成 TSID,HoraeDB 默认将使用(TSID,timestamp)作为主键。 - 只设置时间戳列,HoraeDB 将使用
(timestamp)作为主键。
注意:如果同时指定了主键和 Tag 列,那么 Tag 列只是一个额外的信息标识,不会影响主键生成逻辑。
| |
TSID
如果建表时没有设置主键,并且提供了 Tag 列,HoraeDB 会自动生成一个 TSID 列和时间戳列作为主键。TSID 由所有 Tag 列的 hash 值生成,本质上这是一种自动生成 ID 的机制。
1.2 - 标识符
HoraeDB 中表名、列名等标识符不能是保留关键字或以数字和标点符号开始,不过 HoraeDB 允许用反引号引用标识符(`)。在这种情况下,它可以是任何字符串,如 00_table 或 select。
1.3 - 表结构操作
本章介绍表结构相关 SQL 语句:
1.3.1 - ALTER TABLE
使用 ALTER TABLE 可以改变表的结构和参数 .
变更表结构
例如可以使用 ADD COLUMN 增加表的列 :
| |
变更后的表结构如下:
-- DESCRIBE TABLE `t`;
name type is_primary is_nullable is_tag
t timestamp true false false
tsid uint64 true false false
a int false true false
b string false true false
变更表参数
例如可以使用 MODIFY SETTING 修改表的参数 :
| |
上面的 SQL 用来更改 writer_buffer 大小,变更后的建表如下:
| |
除此之外,我们可以修改其 ttl 为 10 天:
| |
1.3.2 - DROP TABLE
基础语法
删除表的基础语法如下:
| |
Drop Table 用来删除一个表,请谨慎使用这个语句,因为会同时删除表的定义和表的数据,并且无法恢复。
1.3.3 - 创建表
基础语法
建表的基础语法如下 ( [] 之间的内容是可选部分):
| |
列定义的语法 :
| |
表选项的语法是键-值对,值用单引号(')来引用。例如:
| |
IF NOT EXISTS
添加 IF NOT EXISTS 时,HoraeDB 在表名已经存在时会忽略建表错误。
定义列
一个列的定义至少应该包含名称和类型部分,支持的类型见 这里。
列默认为可空,即 “NULL " 关键字是隐含的;添加 NOT NULL 时列不可为空。
| |
定义列时可以使用相关的关键字将列标记为 特殊列。
对于 string 的 tag 列,推荐设置为字典类型来减少内存占用:
| |
引擎设置
HoraeDB 支持指定某个表使用哪种引擎,目前支持的引擎类型为 Analytic。注意这个属性设置后不可更改。
分区设置
仅适用于集群部署模式
CREATE TABLE ... PARTITION BY KEY
下面这个例子创建了一个具有 8 个分区的表,分区键为 name:
| |
1.4 - 数据操作
本章介绍数据操作相关的 SQL.
1.4.1 - INSERT
基础语法
写入数据的基础语法如下:
| |
写入一行数据的示例如下:
| |
1.4.2 - SELECT
基础语法
数据查询的基础语法如下:
| |
数据查询的语法和 mysql 类似,示例如下:
| |
1.5 - 常用 SQL
HoraeDB 中有许多实用的 SQL 工具,可以辅助表操作或查询检查。
查看建表语句
| |
SHOW CREATE TABLE 返回指定表的当前版本的创建语句,包括列定义、表引擎和参数选项等。例如:
| |
查看表信息
| |
DESCRIBE 语句返回一个表的详细结构信息,包括每个字段的名称和类型,字段是否为 Tag 或主键,字段是否可空等。
此外,自动生成的字段 tsid 也会展示在结果里。
例如:
| |
返回结果如下:
name type is_primary is_nullable is_tag
t timestamp true false false
tsid uint64 true false false
a int false true false
b string false true false
解释执行计划
| |
EXPLAIN 语句结果展示一个查询如何被执行。例如:
| |
结果如下:
logical_plan
Projection: #MAX(07_optimizer_t.value) AS c1, #AVG(07_optimizer_t.value) AS c2
Aggregate: groupBy=[[#07_optimizer_t.name]], aggr=[[MAX(#07_optimizer_t.value), AVG(#07_optimizer_t.value)]]
TableScan: 07_optimizer_t projection=Some([name, value])
physical_plan
ProjectionExec: expr=[MAX(07_optimizer_t.value)@1 as c1, AVG(07_optimizer_t.value)@2 as c2]
AggregateExec: mode=FinalPartitioned, gby=[name@0 as name], aggr=[MAX(07_optimizer_t.value), AVG(07_optimizer_t.value)]
CoalesceBatchesExec: target_batch_size=4096
RepartitionExec: partitioning=Hash([Column { name: \"name\", index: 0 }], 6)
AggregateExec: mode=Partial, gby=[name@0 as name], aggr=[MAX(07_optimizer_t.value), AVG(07_optimizer_t.value)]
ScanTable: table=07_optimizer_t, parallelism=8, order=None
1.6 - 配置项
建表时可以使用下列的选项配置引擎:
enable_ttl:布尔类型,默认为true,当一个表配置 TTL 时,早于ttl的数据不会被查询到并且会被删除。ttl:duration类型,默认值为7d,此项定义数据的生命周期,只在enable_ttl为true的情况下使用。storage_format:string类型,数据存储的格式,有两种可选:columnar, 默认值hybrid, 注意:此功能仍在开发中,将来可能会发生变化。
上述两种存储格式详见 存储格式 部分。
存储格式
HoraeDB 支持两种存储格式,一个是 columnar, 这是传统的列式格式,一个物理列中存储表的一个列。
| |
另一个是 hybrid, 当前还在实验阶段的存储格式,用于在列式存储中模拟面向行的存储,以加速经典的时序查询。
在经典的时序场景中,如 IoT 或 DevOps,查询通常会先按系列 ID(或设备 ID)分组,然后再按时间戳分组。
为了在这些场景中实现良好的性能,数据的物理布局应该与这种风格相匹配, hybrid 格式就是这样提出的。
| |
- 在一个文件中,同一个主键(例如设备 ID)的数据会被压缩到一行。
- 除了主键之外的列被分成两类:
collapsible, 这些列会被压缩成一个 list,常用于时序表中的field字段。- 注意: 当前仅支持定长的字段
non-collapsible, 这些列只能包含一个去重值,常用于时序表中的tag字段。- 注意: 当前仅支持字符串类型
- 另外多加了两个字段,
minTime和maxTime, 用于查询中过滤不必要的数据。- 注意: 暂未实现此能力
示例
| |
这段语句会创建一个混合存储格式的表, 这种情况下用户可以通过 parquet-tools查看数据格式. 上面定义的表的 parquet 结构如下所示:
message arrow_schema {
optional group ts (LIST) {
repeated group list {
optional int64 item (TIMESTAMP(MILLIS,false));
}
}
required int64 tsid (INTEGER(64,false));
optional binary tag1 (STRING);
optional binary tag2 (STRING);
optional group value1 (LIST) {
repeated group list {
optional double item;
}
}
optional group value2 (LIST) {
repeated group list {
optional int32 item;
}
}
}
1.7 - 标量函数
HoraeDB SQL 基于 DataFusion 实现,支持的标量函数如下。更多详情请参考: Datafusion
数值函数
| 函数 | 描述 |
|---|---|
| abs(x) | 绝对值 |
| acos(x) | 反余弦 |
| asin(x) | 反正弦 |
| atan(x) | 反正切 |
| atan2(y, x) | y/x 的反正切 |
| ceil(x) | 小于或等于参数的最接近整数 |
| cos(x) | 余弦 |
| exp(x) | 指数 |
| floor(x) | 大于或等于参数的最接近整数 |
| ln(x) | 自然对数 |
| log10(x) | 以 10 为底的对数 |
| log2(x) | 以 2 为底的对数 |
| power(base, exponent) | 幂函数 |
| round(x) | 四舍五入 |
| signum(x) | 根据参数的正负返回 -1、0、+1 |
| sin(x) | 正弦 |
| sqrt(x) | 平方根 |
| tan(x) | 正切 |
| trunc(x) | 截断计算,取整(向零取整) |
条件函数
| 函数 | 描述 |
|---|---|
| coalesce | 如果它的参数中有一个不为 null,则返回第一个参数,如果所有参数均为 null,则返回 null。当从数据库中检索数据用于显示时,它经常用于用默认值替换 null 值。 |
| nullif | 如果 value1 等于 value2,则返回 null 值;否则返回 value1。这可用于执行与 coalesce 表达式相反的操作 |
字符函数
| 函数 | 描述 |
|---|---|
| ascii | 返回参数的第一个字符的 ascii 数字编码。在 UTF8 编码下,返回字符的 Unicode 码点。在其他多字节编码中,参数必须是 ASCII 字符。 |
| bit_length | 返回字符串的比特位数。 |
| btrim | 从字符串的开头和结尾删除给定字符串中的字符组成的最长字符串 |
| char_length | 等效于 length。 |
| character_length | 等效于 length。 |
| concat | 将两个或多个字符串合并为一个字符串。 |
| concat_ws | 使用给定的分隔符组合两个值。 |
| chr | 根据数字码返回字符。 |
| initcap | 将字符串中每个单词的首字母大写。 |
| left | 返回字符串的指定最左边字符。 |
| length | 返回字符串中字符的数量。 |
| lower | 将字符串中的所有字符转换为它们的小写。 |
| lpad | 使用特定字符集将字符串左填充到给定长度。 |
| ltrim | 从字符串的开头删除由字符中的字符组成的最长字符串(默认为空格)。 |
| md5 | 计算给定字符串的 MD5 散列值。 |
| octet_length | 等效于 length。 |
| repeat | 返回一个由输入字符串重复指定次数组成的字符串。 |
| replace | 替换字符串中所有子字符串的出现为新子字符串。 |
| reverse | 反转字符串。 |
| right | 返回字符串的指定最右边字符。 |
| rpad | 使用特定字符集将字符串右填充到给定长度。 |
| rtrim | 从字符串的结尾删除包含 characters 中任何字符的最长字符串。 |
| digest | 计算给定字符串的散列值。 |
| split_part | 按指定分隔符拆分字符串,并从结果数组中返回 |
| starts_with | 检查字符串是否以给定字符串开始 |
| strpos | 搜索字符串是否包含一个给定的字符串,并返回位置 |
| substr | 提取子字符串 |
| translate | 把字符串翻译成另一种字符集 Translates one set of characters into another. |
| trim | 移除字符串两侧的空白字符或其他指定字符。 |
| upper | 将字符串中的所有字符转换为它们的大写。 |
正则函数
| 函数 | 描述 |
|---|---|
| regexp_match | 判断一个字符串是否匹配正则表达式 |
| regexp_replace | 使用新字符串替换正则匹配的字符串中内容 |
时间函数
| 函数 | 描述 |
|---|---|
| to_timestamp | 将字符串转换为 Timestamp(Nanoseconds,None)类型。 |
| to_timestamp_millis | 将字符串转换为 Timestamp(Milliseconds,None)类型。 |
| to_timestamp_micros | 将字符串转换为 Timestamp(Microseconds,None)类型。 |
| to_timestamp_seconds | 将字符串转换为 Timestamp(Seconds,None)类型。 |
| extract | 从日期/时间值中检索年份或小时等子字段。 |
| date_part | 从日期/时间值中检索子字段。 |
| date_trunc | 将日期/时间值截断到指定的精度。 |
| date_bin | 将日期/时间值按指定精度进行分组。 |
| from_unixtime | 将 Unix 时代转换为 Timestamp(Nanoseconds,None)类型。 |
| now | 作为 Timestamp(Nanoseconds,UTC)返回当前时间。 |
其他函数
| Function | 描述 |
|---|---|
| array | 创建有一个数组 |
| arrow_typeof | 返回内置的数据类型 |
| in_list | 检测数值是否在 list 里面 |
| random | 生成随机值 |
| sha224 | sha224 |
| sha256 | sha256 |
| sha384 | sha384 |
| sha512 | sha512 |
| to_hex | 转换为 16 进制 |
1.8 - 聚合函数
HoraeDB SQL 基于 DataFusion 实现,支持的聚合函数如下。更多详情请参考: Datafusion
常用
| 函数 | 描述 |
|---|---|
| min | 最小值 |
| max | 最大值 |
| count | 求行数 |
| avg | 平均值 |
| sum | 求和 |
| array_agg | 把数据放到一个数组 |
统计
| 函数 | 描述 |
|---|---|
| var / var_samp | 返回给定列的样本方差 |
| var_pop | 返回给定列的总体方差 |
| stddev / stddev_samp | 返回给定列的样本标准差 |
| stddev_pop | 返回给定列的总体标准差 |
| covar / covar_samp | 返回给定列的样本协方差 |
| covar_pop | 返回给定列的总体协方差 |
| corr | 返回给定列的相关系数 |
估值函数
| 函数 | 描述 |
|---|---|
| approx_distinct | 返回输入值的近似去重数量(HyperLogLog) |
| approx_median | 返回输入值的近似中位数,它是 approx_percentile_cont(x, 0.5) 的简单写法 |
| approx_percentile_cont | 返回输入值的近似百分位数(TDigest),其中 p 是 0 和 1(包括)之间的 float64,等同于 approx_percentile_cont_with_weight(x, 1, p) |
| approx_percentile_cont_with_weight | 返回输入值带权重的近似百分位数(TDigest),其中 w 是权重列表达式,p 是 0 和 1(包括)之间的 float64 |
2 - 集群部署
在快速开始部分我们已经介绍过单机版本 HoraeDB 的部署。
除此之外,HoraeDB 作为一个分布式时序数据库,多个 HoraeDB 实例能够以集群的方式提供可伸缩和高可用的数据服务。
由于目前 HoraeDB 对于 Kubernetes 的支持还在开发之中,目前 HoraeDB 集群部署只能通过手动完成,集群部署的模式主要有两种,两者的区别在于是否需要部署 HoraeMeta,对于 NoMeta 的模式,我们仅建议在测试场景下使用。
2.1 - NoMeta 模式
注意:此功能仅供测试使用,不推荐生产使用,相关功能将来可能会发生变化。
本章介绍如何部署一个静态(无 HoraeMeta)的 HoraeDB 集群。
在没有 HoraeMeta 的情况下,利用 HoraeDB 服务端针对表名提供了可配置的路由功能即可实现集群化部署,为此我们需要提供一个包含路由规则的正确配置。根据这个配置,请求会被发送到集群中的每个 HoraeDB 实例。
目标
本文的目标是:在同一台机器上部署一个集群,这个集群包含两个 HoraeDB 实例。
如果想要部署一个更大规模的集群,参考此方案也可以进行部署。
准备配置文件
基础配置
HoraeDB 的基础配置如下:
| |
为了在同一个机器上部署两个实例,我们需要为每个实例配置不同的服务端口和数据目录。
实例 HoraeDB_0 的配置如下:
| |
实例 HoraeDB_1 的配置如下:
| |
Schema 和 Shard
接下来我们需要定义 Schema 和分片以及路由规则。
如下定义了 Schema 和分片:
| |
上述的配置中,定义了两个 Schema:
public_0有两个分片在HoraeDB_0实例上。public_1有两个分片同时在HoraeDB_0和HoraeDB_1实例上。
路由规则
定义 Schema 和分片后,需要定义路由规则,如下是一个前缀路由规则:
| |
在这个规则里,public_0 中表名以 prod_ 为前缀的所有表属于,相关操作会被路由到 shard_0 也就是 HoraeDB_0 实例。 public_0 中其他的表会以 hash 的方式路由到 shard_0 和 shard_1.
在前缀规则之外,我们也可以定义一个 hash 规则:
| |
这个规则告诉 HoraeDB, public_1 的所有表会被路由到 public_1 的 shard_0 and shard_1, 也就是 HoraeDB0 和 HoraeDB_1.
实际上如果没有定义 public_1 的路由规则,这是默认的路由行为。
HoraeDB_0 和 HoraeDB_1 实例完整的配置文件如下:
| |
| |
我们给这两份不同的配置文件分别命名为 config_0.toml 和 config_1.toml;
但是在实际环境中不同的实例可以部署在不同的服务器上,也就是说,不同的实例没有必要设置不同的服务端口和数据目录,这种情况下实例的配置可以使用同一份配置文件。
启动 HoraeDB
配置准备好后,我们就可以开始启动 HoraeDB 容器了。
启动命令如下:
| |
容器启动成功后,两个实例的 HoraeDB 集群就搭建完成了,可以开始提供读写服务。
2.2 - WithMeta 模式
本文展示如何部署一个由 HoraeMeta 控制的 HoraeDB 集群,有了 HoraeMeta 提供的服务,如果 HoraeDB 使用存储不在本地的话,就可以实现很多分布式特性,比如水平扩容、负载均衡、服务高可用等。
部署 HoraeMeta
HoraeMeta 是 HoraeDB 分布式模式的核心服务之一,用于管理 HoraeDB 节点的调度,为 HoraeDB 集群提供高可用、负载均衡、集群管控等能力。 HoraeMeta 本身通过嵌入式的 ETCD 保障高可用。此外,ETCD 的服务也被暴露给 HoraeDB 用于实现分布式锁使用。
编译打包
- 安装 Golang,版本号 >= 1.19。
- 在项目根目录下使用
make build进行编译打包。
部署方式
启动配置
目前 HoraeMeta 支持以配置文件和环境变量两种方式来指定服务启动配置。我们提供了配置文件方式启动的示例,具体可以参考 config。 环境变量的配置优先级高于配置文件,当同时存在时,以环境变量为准。
动态拓扑和静态拓扑
即使使用了 HoraeMeta 来部署 HoraeDB 集群,也可以选择静态拓扑或动态拓扑。对于静态拓扑,表的分布在集群初始化后是静态的,而对于动态拓扑,表可以在不同的 HoraeDB 节点之间进行动态迁移以达到负载平衡或者 failover 的目的。但是动态拓扑只有在 HoraeDB 节点使用的存储是非本地的情况下才能启用,否则会因为表的数据是持久化在本地,当表转移到不同的 HoraeDB 节点时会导致数据损坏。
目前,HoraeMeta 默认关闭集群拓扑的动态调度,并且在本篇指南中,这个选项也不会被开启,因为指南中的例子采用的是本地存储。如果要启用动态调度,可以将 TOPOLOGY_TYPE 设置为 dynamic(默认为 static),之后负载均衡和 failover 将会起作用。但是需要注意的是,如果底层存储是本地磁盘,则不要启用它。
此外对于静态拓扑,参数 DEFAULT_CLUSTER_NODE_COUNT 表示已部署集群中 HoraeDB 节点的数量,应该被设置为 HoraeDB 服务器的实际机器数,这个参数非常重要,因为集群初始化完毕之后,HoraeDB 集群将无法再增减机器。
启动实例
HoraeMeta 基于 etcd 实现高可用,在线上环境我们一般部署多个节点,但是在本地环境和测试时,可以直接部署单个节点来简化整个部署流程。
- 单节点
| |
- 多节点
| |
如果 HoraeDB 底层采用的是远程存储,可以环境变量来开启动态调度:只需将 -e ENABLE_SCHEDULE=true 加入到 docker run 命令中去。
部署 HoraeDB
在 NoMeta 模式中,由于 HoraeDB 集群拓扑是静态的,因此 HoraeDB 只需要一个本地存储来作为底层的存储层即可。但是在 WithMeta 模式中,集群的拓扑是可以变化的,因此如果 HoraeDB 的底层存储使用一个独立的存储服务的话,HoraeDB 集群就可以获得分布式系统的一些特性:高可用、负载均衡、水平扩展等。
当然,HoraeDB 仍然可以使用本地存储,这样的话,集群的拓扑仍然是静态的。
存储相关的配置主要包括两个部分:
- Object Storage
- WAL Storage
注意:在生产环境中如果我们把 HoraeDB 部署在多个节点上时,请按照如下方式把机器的网络地址设置到环境变量中:
| |
注意,此网络地址用于 HoraeMeta 和 HoraeDB 通信使用,需保证网络联通可用。
Object Storage
本地存储
类似 NoMeta 模式,我们仍然可以为 HoraeDB 配置一个本地磁盘作为底层存储:
| |
OSS
Aliyun OSS 也可以作为 HoraeDB 的底层存储,以此提供数据容灾能力。下面是一个配置示例,示例中的模版变量需要被替换成实际的 OSS 参数才可以真正的使用:
| |
S3
Amazon S3 也可以作为 HoraeDB 的底层存储,下面是一个配置示例,示例中的模版变量需要被替换成实际的 S3 参数才可以真正的使用:
| |
WAL Storage
RocksDB
基于 RocksDB 的 WAL 也是一种本地存储,无第三方依赖,可以很方便的快速部署:
| |
OceanBase
如果已经有了一个部署好的 OceanBase 集群的话,HoraeDB 可以使用它作为 WAL Storage 来保证其数据的容灾性。下面是一个配置示例,示例中的模版变量需要被替换成实际的 OceanBase 集群的参数才可以真正的使用:
| |
Kafka
如果你已经部署了一个 Kafka 集群,HoraeDB 可以也可以使用它作为 WAL Storage。下面是一个配置示例,示例中的模版变量需要被替换成实际的 Kafka 集群的参数才可以真正的使用:
| |
Meta 客户端配置
除了存储层的配置外,HoraeDB 需要 HoraeMeta 相关的配置来与 HoraeMeta 集群进行通信:
[cluster.meta_client]
cluster_name = 'defaultCluster'
meta_addr = 'http://{HoraeMetaAddr}:2379'
lease = "10s"
timeout = "5s"
[cluster_deployment.etcd_client]
server_addrs = ['http://{HoraeMetaAddr}:2379']
完整配置
将上面提到的所有关键配置合并之后,我们可以得到一个完整的、可运行的配置。为了让这个配置可以直接运行起来,配置中均采用了本地存储:基于 RocksDB 的 WAL 和本地磁盘的 Object Storage:
| |
将这个配置命名成 config.toml。至于使用远程存储的配置示例在下面我们也提供了,需要注意的是,配置中的相关参数需要被替换成实际的参数才能真正使用:
启动集群
首先,我们先启动 HoraeMeta:
| |
HoraeMeta 启动好了,没有问题之后,就可以把 HoraeDB 的容器创建出来: TODO: 补充完整
3 - SDK 文档
3.1 - Go
安装
go get github.com/apache/incubator-horaedb-client-go
你可以在这里找到最新的版本 here.
如何使用
初始化客户端
| |
| 参数名称 | 说明 |
|---|---|
| defaultDatabase | 所使用的 database,可以被单个 Write 或者 SQLRequest 请求中的 database 覆盖 |
| RPCMaxRecvMsgSize | grpc MaxCallRecvMsgSize 配置, 默认是 1024 _ 1024 _ 1024 |
| RouteMaxCacheSize | 如果 router 客户端中的 路由缓存超过了这个值,将会淘汰最不活跃的直至降低这个阈值, 默认是 10000 |
注意: HoraeDB 当前仅支持预创建的 public database , 未来会支持多个 database。
管理表
HoraeDB 使用 SQL 来管理表格,比如创建表、删除表或者新增列等等,这和你在使用 SQL 管理其他的数据库时没有太大的区别。
为了方便使用,在使用 gRPC 的 write 接口进行写入时,如果某个表不存在,HoraeDB 会根据第一次的写入自动创建一个表。
当然你也可以通过 create table 语句来更精细化的管理的表(比如添加索引等)。
创建表的样例
| |
删除表的样例
| |
构建写入数据
| |
写入数据
| |
查询数据
| |
示例
你可以在这里找到完整的示例。
3.2 - Java
介绍
HoraeDBClient 是 HoraeDB 的高性能 Java 版客户端。
环境要求
Java 8 及以上
依赖
| |
最新的版本可以从这里获取。
初始化客户端
| |
客户端初始化至少需要三个参数:
- EndPoint: 127.0.0.1
- Port: 8831
- RouteMode: DIRECT/PROXY
这里重点解释下 RouteMode 参数,PROXY 模式用在客户端和服务端存在网络隔离,请求需要经过转发的场景;DIRECT 模式用在客户端和服务端网络连通的场景,节省转发的开销,具有更高的性能。
更多的参数配置详情见 configuration。
注意: HoraeDB 当前仅支持默认的 public database , 未来会支持多个 database。
建表
为了方便使用,在使用 gRPC 的 write 接口进行写入时,如果某个表不存在,HoraeDB 会根据第一次的写入自动创建一个表。
当然你也可以通过 create table 语句来更精细化的管理的表(比如添加索引等)。
下面的建表语句(使用 SDK 的 SQL API)包含了 HoraeDB 支持的所有字段类型:
| |
删表
下面是一个删表的示例:
| |
数据写入
首先我们需要构建数据,示例如下:
| |
然后使用 write 接口写入数据,示例如下:
| |
详情见 write
数据查询
| |
详情见 read
流式读写
HoraeDB 支持流式读写,适用于大规模数据读写。
| |
详情见 streaming
3.3 - Python
介绍
horaedb-client 是 HoraeDB python 客户端.
借助于 PyO3,python 客户端的实现实际上是基于 rust 客户端 的封装。
本手册将会介绍 python client 的一些基本用法,其中涉及到的完整示例,可以查看该示例代码.
环境要求
- Python >= 3.7
安装
| |
你可以在这里找到最新的版本 here.
初始化客户端
首先介绍下如何初始化客户端,代码示例如下:
| |
代码的最开始部分是依赖库的导入,在后面的示例中将省略这部分。
客户端初始化需要至少两个参数:
Endpoint: 服务端地址,由 ip 和端口组成,例如127.0.0.1:8831;Mode: 客户端和服务端通信模式,有两种模式可供选择:Direct和Proxy。
这里重点介绍下通信模式 Mode, 当客户端可以访问所有的服务器的时候,建议采用 Direct 模式,以减少转发开销;但是如果客户端访问服务器必须要经过网关,那么只能选择 Proxy 模式。
至于 default_database,会在执行 RPC 请求时未通过 RpcContext 设置 database 的情况下,将被作为目标 database 使用。
最后,通过配置 RpcConfig, 可以管理客户端使用的资源和调整其性能,所有的配置参数可以参考这里.
建表
为了方便使用,在使用 gRPC 的 write 接口进行写入时,如果某个表不存在,HoraeDB 会根据第一次的写入自动创建一个表。
当然你也可以通过 create table 语句来更精细化的管理的表(比如添加索引等)。
初始化客户端后,建表示例如下:
| |
RpcContext 可以用来指定目标 database (可以覆盖在初始化的时候设置的 default_space) 和超时参数。
数据写入
可以使用 PointBuilder 来构建一个 point(实际上就是数据集的一行),多个 point 构成一个写入请求。
示例如下:
| |
数据查询
通过 sql_query 接口, 可以方便地从服务端查询数据:
req = SqlQueryRequest(['demo'], 'select * from demo')
event_loop = asyncio.get_event_loop()
resp = event_loop.run_until_complete(async_query(client, ctx, req))
如示例所展示, 构建 SqlQueryRequest 需要两个参数:
- 查询 sql 中涉及到的表;
- 查询 sql.
当前为了查询的性能,第一个参数是必须的。
查询到数据后,逐行逐列处理数据的示例如下:
| |
删表
和创建表类似,我们可以使用 sql 来删除表:
| |
3.4 - Rust
安装
| |
你可以在这里找到最新的版本 here.
初始化客户端
首先,我们需要初始化客户端。
- 创建客户端的 builder,你必须设置
endpoint和mode:endpoint是类似 “ip/domain_name:port” 形式的字符串。mode用于指定访问 HoraeDB 服务器的方式,关于 mode 的详细信息。
| |
- 创建和设置
rpc_config,可以按需进行定义或者直接使用默认值,更多详细参数请参考这里:
| |
- 设置
default_database,这会在执行 RPC 请求时未通过 RpcContext 设置 database 的情况下,将被作为目标 database 使用。
| |
- 最后,我们从 builder 中创建客户端:
| |
管理表
为了方便使用,在使用 gRPC 的 write 接口进行写入时,如果某个表不存在,HoraeDB 会根据第一次的写入自动创建一个表。
当然你也可以通过 create table 语句来更精细化的管理的表(比如添加索引等)。
- 建表:
| |
- 删表:
| |
写入数据
我们支持使用类似 InfluxDB 的时序数据模型进行写入。
- 利用
PointBuilder创建point,tag value和field value的相关数据结构为Value,[Value的详细信息](detail about Value](https://github.com/apache/incubator-horaedb-client-rs/blob/main/src/model/value.rs:
| |
- 将
point添加到write request中:
| |
- 创建
rpc_ctx,同样地可以按需设置或者使用默认值,rpc_ctx的详细信息请参考这里:
| |
- 最后,利用客户端写入数据到服务器:
| |
Sql query
我们支持使用 sql 进行数据查询。
- 在
sql query request中指定相关的表和 sql 语句:
| |
- 利用客户端进行查询:
| |
示例
你可以在本项目的仓库中找到完整的例子。
4 - 运维文档
本章介绍 HoraeDB 的运维相关的操作,包括表相关操作,设置访问黑名单,已经如何监控 HoraeDB。未来还会介绍集群扩容,容灾相关:
4.1 - 监控
HoraeDB 支持使用 Prometheus 和 Grafana 做自监控。
Prometheus
Prometheus 是非常流行的系统和服务监控系统。
配置
把下面的配置保存到 prometheus.yml 文件中。比如,在 tmp 目录下,文件地址为 /tmp/prometheus.yml。
有两个 HoraeDB http 服务启动在 localhost:5440、localhost:5441。
| |
Prometheus 详细配置见这里。
运行
你可以使用 docker 来运行 Prometheus。Docker 镜像在这里可以找到。
docker run \
-d --name=prometheus \
-p 9090:9090 \
-v /tmp/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus:v2.41.0
更多 Prometheus 安装方法,参考这里。
Grafana
Grafana 是一个非常流行的可观察性和数据可视化平台。
运行
你可以使用 docker 来运行 Grafana。Docker 镜像在这里可以找到。
docker run -d --name=grafana -p 3000:3000 grafana/grafana:9.3.6
默认用户密码是 admin/admin.
运行上面命令后,grafana 可以用浏览器打开 http://127.0.0.1:3000。
更多 Grafana 安装方法,参考这里。
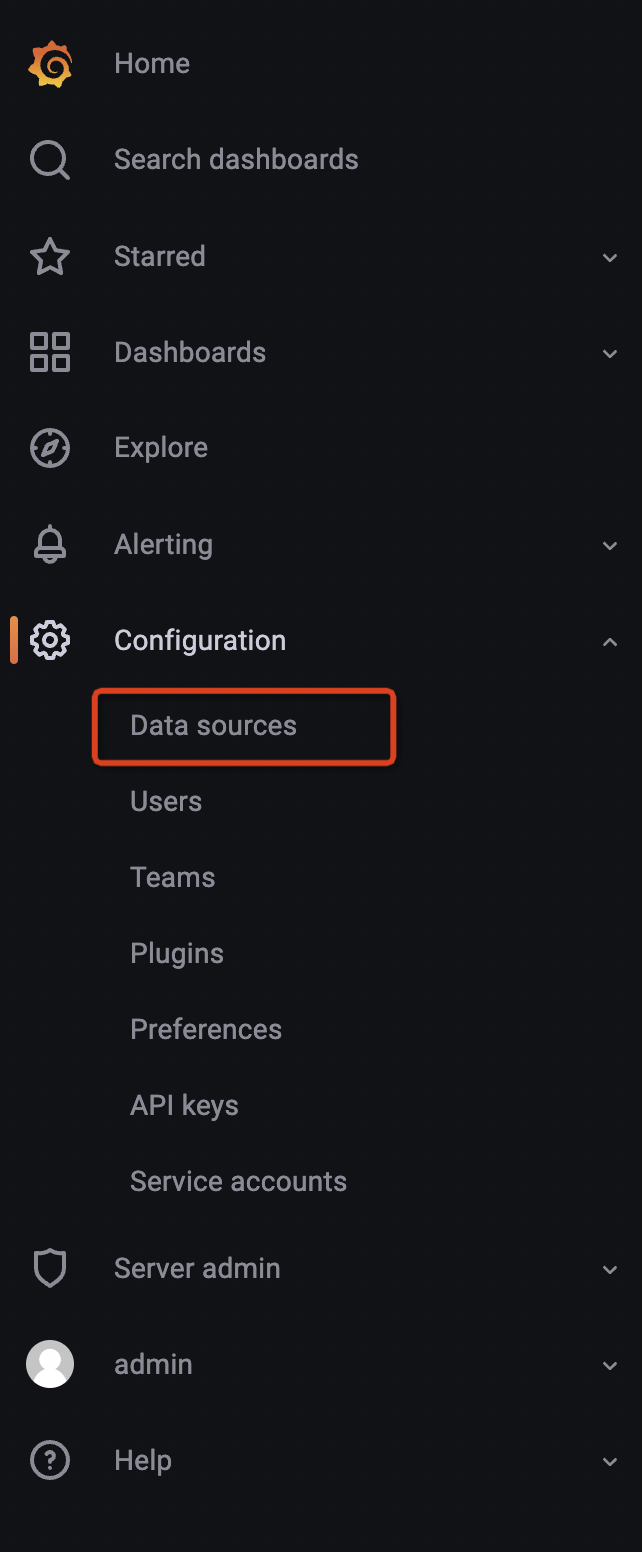
配置数据源
- 将光标悬停在配置(齿轮)图标上。
- 选择数据源。
- 选择 Prometheus 数据源。
注意: Prometheus 的 url 需要填写成这样 http://your_ip:9090, your_ip 换成本地地址。
更详细的配置可以参考这里。
导入监控页面
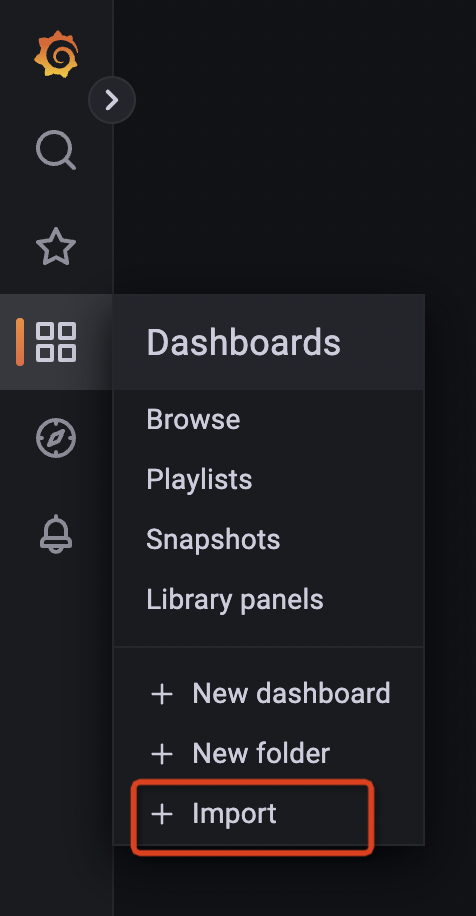
HoraeDB 指标
当导入完成后,你可以看到如下页面:
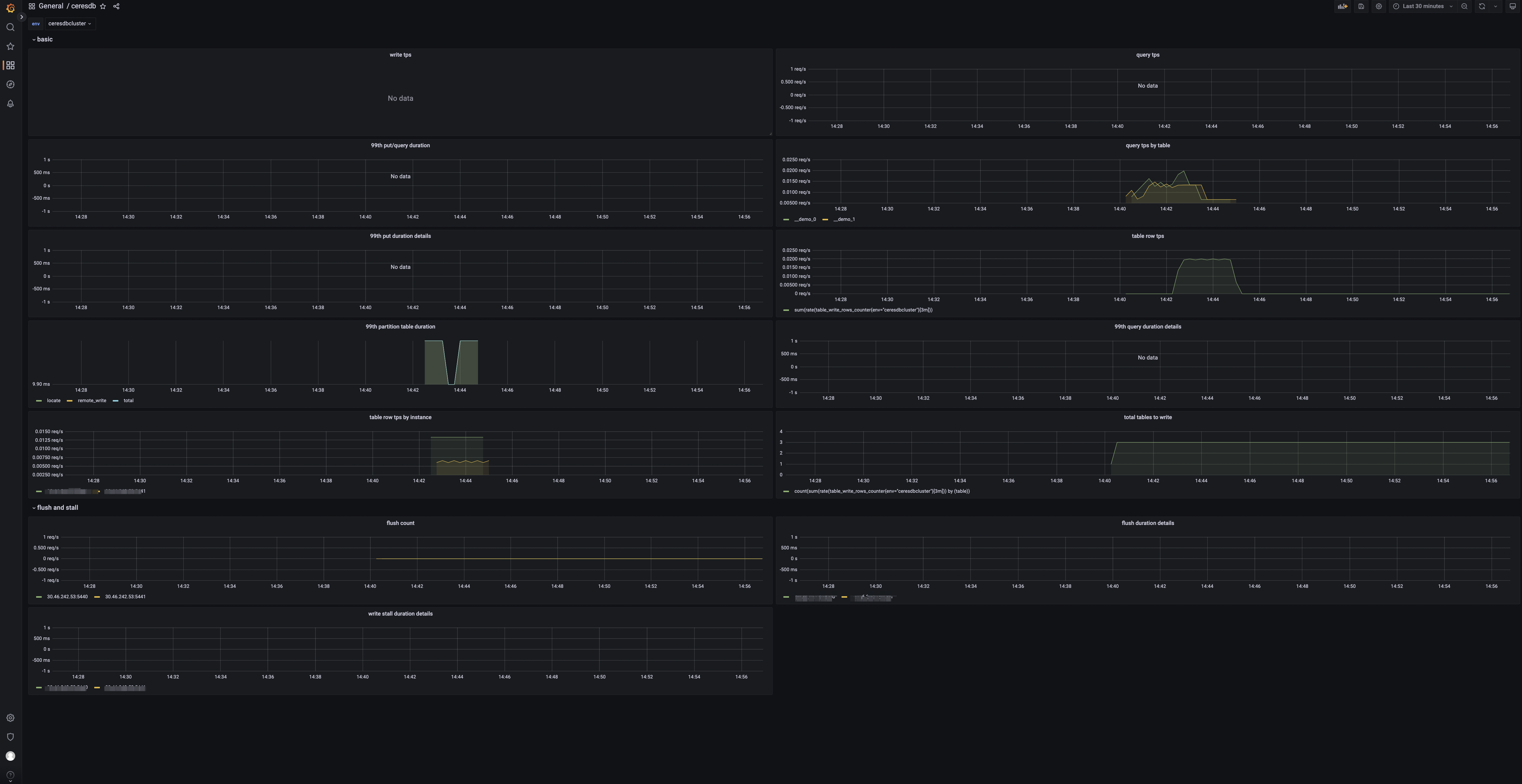
Panels
- tps: 集群写入请求数。
- qps: 集群查询请求数。
- 99th query/write duration: 查询写入的 99% 分位数。
- table query by table: 表查询请求数。
- 99th write duration details by instance: 写入耗时的 99% 分位数。
- 99th query duration details by instance: 查询耗时的 99% 分位数。
- 99th write partition table duration: 分区表查询耗时的 99% 分位数。
- table rows: 表的写入行数。
- table rows by instance: 实例级别的写入行数。
- total tables to write: 有数据写入的表数目。
- flush count: HoraeDB flush 的次数。
- 99th flush duration details by instance: 实例级别的 flush 耗时的 99% 分位数。
- 99th write stall duration details by instance: 实例级别的写入停顿时间的 99% 分位数 。
4.2 - 系统表
查询 Table 信息
类似于 Mysql’s information_schema.tables, HoraeDB 提供 system.public.tables 存储表信息。
system.public.tables 表的列如下 :
- timestamp([TimeStamp])
- catalog([String])
- schema([String])
- table_name([String])
- table_id([Uint64])
- engine([String])
通过表名查询表信息示例如下:
| |
返回结果
| |
4.3 - 表操作
HoraeDB 支持标准的 SQL,用户可以使用 Http 协议创建表和读写表。更多内容可以参考 SQL 语法
创建表
示例如下
| |
写数据
示例如下
| |
读数据
示例如下
| |
查询表信息
示例如下
| |
Drop 表
示例如下
| |
查询表路由
示例如下
| |
4.4 - 集群运维
集群运维接口的使用前提是,HoraeDB 部署为使用 HoraeMeta 的集群模式。
运维接口
注意: 如下接口在实际使用时需要将 127.0.0.1 替换为 HoraeMeta 的真实地址。
- 查询表元信息 当 tableNames 不为空的时候,使用 tableNames 进行查询。 当 tableNames 为空的时候,使用 ids 进行查询。使用 ids 查询的时候,schemaName 不生效。
curl --location 'http://127.0.0.1:8080/api/v1/table/query' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"schemaName":"public",
"names":["demo1", "__demo1_0"],
}'
curl --location 'http://127.0.0.1:8080/api/v1/table/query' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"ids":[0, 1]
}'
- 查询表的路由信息
curl --location --request POST 'http://127.0.0.1:8080/api/v1/route' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"schemaName":"public",
"table":["demo"]
}'
- 查询节点对应的 Shard 信息
curl --location --request POST 'http://127.0.0.1:8080/api/v1/getNodeShards' \
--header 'Content-Type: application/json' \
-d '{
"ClusterName":"defaultCluster"
}'
- 查询 Shard 对应的表信息 如果 shardIDs 为空时,查询所有 shard 上表信息。
curl --location --request POST 'http://127.0.0.1:8080/api/v1/getShardTables' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"shardIDs": [1,2]
}'
- 删除指定表的元数据
curl --location --request POST 'http://127.0.0.1:8080/api/v1/dropTable' \
--header 'Content-Type: application/json' \
-d '{
"clusterName": "defaultCluster",
"schemaName": "public",
"table": "demo"
}'
- Shard 切主
curl --location --request POST 'http://127.0.0.1:8080/api/v1/transferLeader' \
--header 'Content-Type: application/json' \
-d '{
"clusterName":"defaultCluster",
"shardID": 1,
"oldLeaderNodeName": "127.0.0.1:8831",
"newLeaderNodeName": "127.0.0.1:18831"
}'
- Shard 分裂
curl --location --request POST 'http://127.0.0.1:8080/api/v1/split' \
--header 'Content-Type: application/json' \
-d '{
"clusterName" : "defaultCluster",
"schemaName" :"public",
"nodeName" :"127.0.0.1:8831",
"shardID" : 0,
"splitTables":["demo"]
}'
- 创建 HoraeDB 集群
curl --location 'http://127.0.0.1:8080/api/v1/clusters' \
--header 'Content-Type: application/json' \
--data '{
"name":"testCluster",
"nodeCount":3,
"ShardTotal":9,
"enableSchedule":true,
"topologyType":"static"
}'
- 更新 HoraeDB 集群
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/clusters/{NewClusterName}' \
--header 'Content-Type: application/json' \
--data '{
"nodeCount":28,
"shardTotal":128,
"enableSchedule":true,
"topologyType":"dynamic"
}'
- 列出 HoraeDB 集群
curl --location 'http://127.0.0.1:8080/api/v1/clusters'
- 修改
enableSchedule
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/clusters/{ClusterName}/enableSchedule' \
--header 'Content-Type: application/json' \
--data '{
"enable":true
}'
- 查询
enableSchedule
curl --location 'http://127.0.0.1:8080/api/v1/clusters/{ClusterName}/enableSchedule'
- 更新限流器
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/flowLimiter' \
--header 'Content-Type: application/json' \
--data '{
"limit":1000,
"burst":10000,
"enable":true
}'
- 查询限流器信息
curl --location 'http://127.0.0.1:8080/api/v1/flowLimiter'
- HoraeMeta 列出节点
curl --location 'http://127.0.0.1:8080/api/v1/etcd/member'
- HoraeMeta 节点切主
curl --location 'http://127.0.0.1:8080/api/v1/etcd/moveLeader' \
--header 'Content-Type: application/json' \
--data '{
"memberName":"meta1"
}'
- HoraeMeta 节点扩容
curl --location --request PUT 'http://127.0.0.1:8080/api/v1/etcd/member' \
--header 'Content-Type: application/json' \
--data '{
"memberAddrs":["http://127.0.0.1:42380"]
}'
- HoraeMeta 替换节点
curl --location 'http://127.0.0.1:8080/api/v1/etcd/member' \
--header 'Content-Type: application/json' \
--data '{
"oldMemberName":"meta0",
"newMemberAddr":["http://127.0.0.1:42380"]
}'
4.5 - 黑名单
增加黑名单
如果你想限制某个表的查询,可以把表名加到 read_block_list 中。
示例如下:
| |
返回结果:
| |
设置黑名单
设置黑名单的操作首先会清理已有的列表,然后再把新的表设置进去。
示例如下:
| |
返回结果:
| |
删除黑名单
如果你想把表从黑名单中移除,可以使用如下命令:
| |
返回结果:
| |
5 - 周边生态
HoraeDB 是一个开放的系统,鼓励合作和创新,允许开发者使用最适合其自身需求的系统。目前 HoraeDB 支持以下系统:
5.1 - InfluxDB
InfluxDB 是一个时间序列数据库,旨在处理高写入和查询负载。它是 TICK 堆栈的一个组成部分。InfluxDB 旨在用作涉及大量时间戳数据的任何用例的后备存储,包括 DevOps 监控、应用程序指标、物联网传感器数据和实时分析。
HoraeDB 支持 InfluxDB v1.8 写入和查询 API。
注意:用户需要将以下配置添加到服务器的配置中才能尝试 InfluxDB 写入/查询。
[server.default_schema_config]
default_timestamp_column_name = "time"
写入
curl -i -XPOST "http://localhost:5440/influxdb/v1/write" --data-binary '
demo,tag1=t1,tag2=t2 field1=90,field2=100 1679994647000
demo,tag1=t1,tag2=t2 field1=91,field2=101 1679994648000
demo,tag1=t11,tag2=t22 field1=90,field2=100 1679994647000
demo,tag1=t11,tag2=t22 field1=91,field2=101 1679994648000
'
Post 的内容采用的是 InfluxDB line protocol 格式。
measurement 将映射到 HoraeDB 中的一个表,在首次写入时 server 会自动进行建表(注意:创建表的 TTL 是 7d,写入超过当前周期数据会被丢弃)。
例如,在上面插入数据时,HoraeDB 中将创建下表:
CREATE TABLE `demo` (
`tsid` uint64 NOT NULL,
`time` timestamp NOT NULL,
`field1` double,
`field2` double,
`tag1` string TAG,
`tag2` string TAG,
PRIMARY KEY (tsid, time),
timestamp KEY (time))
注意事项
- InfluxDB 在写入时,时间戳精度默认是纳秒,HoraeDB 只支持毫秒级时间戳,用户可以通过
precision参数指定数据精度,HoraeDB 内部会自动转成毫秒精度。 - 暂时不支持诸如
db等查询参数
查询
| |
查询结果和 InfluxDB 查询接口一致:
| |
如何在 Grafana 中使用
HoraeDB 可以用作 Grafana 中的 InfluxDB 数据源。具体方式如下:
- 在新增数据源时,选择 InfluxDB 类型
- 在 HTTP URL 处,输入
http://{ip}:{5440}/influxdb/v1/。对于本地部署的场景,可以直接输入 http://localhost:5440/influxdb/v1/ Save & test
注意事项
暂时不支持诸如 epoch, db 等的查询参数
5.2 - OpenTSDB
OpenTSDB 是基于 HBase 的分布式、可伸缩的时间序列数据库。
写入
HoraeDB 遵循 OpenTSDB put 写入接口。
summary 和 detailed 还未支持。
curl --location 'http://localhost:5440/opentsdb/api/put' \
--header 'Content-Type: application/json' \
-d '[{
"metric": "sys.cpu.nice",
"timestamp": 1692588459000,
"value": 18,
"tags": {
"host": "web01",
"dc": "lga"
}
},
{
"metric": "sys.cpu.nice",
"timestamp": 1692588459000,
"value": 18,
"tags": {
"host": "web01"
}
}]'
metric 将映射到 HoraeDB 中的一个表,在首次写入时 server 会自动进行建表(注意:创建表的 TTL 是 7d,写入超过当前周期数据会被丢弃)。
例如,在上面插入数据时,HoraeDB 中将创建下表:
CREATE TABLE `sys.cpu.nice`(
`tsid` uint64 NOT NULL,
`timestamp` timestamp NOT NULL,
`dc` string TAG,
`host` string TAG,
`value` bigint,
PRIMARY KEY(tsid, timestamp),
TIMESTAMP KEY(timestamp))
ENGINE = Analytic
WITH(arena_block_size = '2097152', compaction_strategy = 'default',
compression = 'ZSTD', enable_ttl = 'true', num_rows_per_row_group = '8192',
segment_duration = '2h', storage_format = 'AUTO', ttl = '7d',
update_mode = 'OVERWRITE', write_buffer_size = '33554432')
查询
暂不支持 OpenTSDB 查询,tracking issue。
5.3 - Prometheus
Prometheus是一个流行的云原生监控工具,由于其可扩展性、可靠性和可伸缩性,被企业广泛采用。它用于从云原生服务(如 Kubernetes 和 OpenShift)中获取指标,并将其存储在时序数据库中。Prometheus 也很容易扩展,允许用户用其他数据库扩展其特性和功能。
HoraeDB 可以作为 Prometheus 的长期存储解决方案,同时支持远程读取和远程写入 API。
配置
你可以通过在prometheus.yml中添加以下几行来配置 Prometheus 使用 HoraeDB 作为一个远程存储:
| |
每一个指标都会对应一个 HoraeDB 中的表:
- 标签(labels)对应字符串类型的
tag列 - 数据的时间戳对应一个 timestamp 类型的
timestmap列 - 数据的值对应一个双精度浮点数类型的
value列
比如有如下 Prometheus 指标:
up{env="dev", instance="127.0.0.1:9090", job="prometheus-server"}
对应 HoraeDB 中如下的表(注意:创建表的 TTL 是 7d,写入超过当前周期数据会被丢弃):
CREATE TABLE `up` (
`timestamp` timestamp NOT NULL,
`tsid` uint64 NOT NULL,
`env` string TAG,
`instance` string TAG,
`job` string TAG,
`value` double,
PRIMARY KEY (tsid, timestamp),
timestamp KEY (timestamp)
);
SELECT * FROM up;
| tsid | timestamp | env | instance | job | value |
|---|---|---|---|---|---|
| 12683162471309663278 | 1675824740880 | dev | 127.0.0.1:9090 | prometheus-server | 1 |